소리소리 ai 기본 플랜(유료) 사용 후기 & ai 커버 제작기

몇 달 전부터 더 심오한 씹덕질을 위해 ai커버 제작방법을 찾아보았고 코랩 등으로 시도도 해보았는데
내 병든 그래픽카드를 혹사할 수 없어서 결국 유료 서비스를 이용하기로 했다.
********ai커버 제작은 시간 빌게이츠들만 하시오*******
준비물
Audacity : 오디오 편집 프로그램, 무료
최소 15분 이상의 학습 데이터 : 노래하는 음성 위주
UVR(Ultimate Vocal Remover) : MR-보이스 분리, 보정 프로그램, 무료
가우디오 스튜디오 : MR-보이스 분리, 무료
소리소리 AI : 커버 제작, 유료
SETP 1. 학습 데이터 제작
커버를 만들고 싶은 대상이 부른 노래를 MR과 분리함
UVR을 이용하면 더 깔끔하게 되는 것 같던데 이 작업이 곡당 3~5분은 걸리는 것 같음
컴도 혹사하는데 시간까지 너무 오래걸려서 나는 가우디오 스튜디오를 이용했다.
Gaudio Studio | 가우디오 스튜디오
Instrument Separation & Noraebang
studio.gaudiolab.io
가입하고 이용할 수 있는데 무료임. 현재 베타버전이라 정식 출시되면 유료가 될지도?

나는 곡을 전부 MP3파일로 갖고 있어서 파일을 직접 업로드했는데
유튜브 URL로도 되는 것 같았음.
곡을 업로드한 뒤 Vocal, Other Instruments를 선택하고 요청하기 누르면 보컬과 MR만 분리해줌.
피아노, 베이스 등 다른 선택지도 누르면 각각의 악기를 분리해주기도 하지만 ai커버에 그거까진 필요 없음
분리가 바로 되는 게 아니라 짧게는 n초~길게는 5분 정도 기다려야 분리작업이 시작됨

그러면 각각 분리된 파일을 다운받을 수 있다.
하지만 이 보컬 파일을 학습 데이터에 그대로 쓰는 것이 아니라 더 깔끔하게 보정 작업을 해주어야 함.
왜냐면 여전히 에코(울림)랑 다른 코러스나 잡음이 잔뜩 낀 상태이기 때문에
이제부터 UVR 프로그램을 사용해줌

어렵게 생겼는데 금방 눈에 익음
1. 스패너 모양 클릭하면 창이 뜨는데
2. 상단 탭 중 다운로드 센터 클릭
3. VR Arch선택하여 UVR-De-Echo-Aggressive 하나 다운로드
4. MDX-Net 선택하여 Reverb HQ, UVR-MDX-NET Karaoke2 총 두 개 다운로드
참고로 Kim Vocal1이란 것도 있는데 이건 MR-보이스 분리 프로그램이기 때문에, 이미 가우디오 스튜디오로 보컬을 분리했다면 굳이 필요하지 않음.
가우디오 안쓰고 직접 분리하고 싶을 경우 Kim Vocal1도 다운받으면 됨
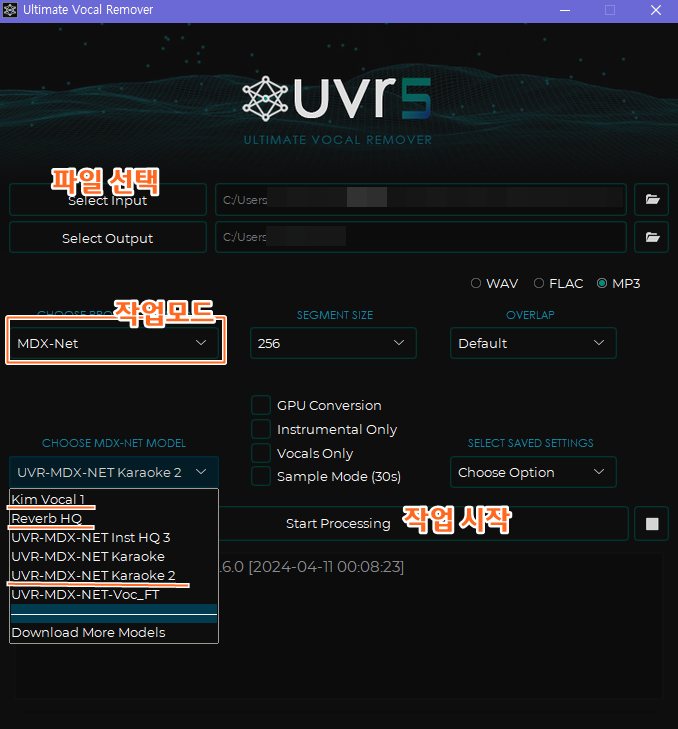
앞서 가우디오 스튜디오에서 추출한 보컬 파일(노래제목_gaudiolab_vocal 파일)을 업로드하고
작업 모드에서 MDX-Net과 VR Arch를 클릭해보면 방금 다운받은 모델 목록이 나옴
- GPU Conversion을 체크하면 그래픽카드까지 동원하는 것 같은데 난 안했음
- Vocals Only를 체크하면 보컬 파일만 생성되는데
난 자꾸 헷갈려서 다 체크 해제했음. 이러면 보컬파일과 MR파일(보컬에서 분리된 잡음) 전부 생성됨
- 파일 형식은 MP3
작업 과정은
(0. 가우디오로 분리 안한 사람은 Kim Vocal 1 실행하여 MR-보이스 분리)
1. 파일 선택에서 아까 가우디오로 분리한 보컬 파일 (노래제목_gaudiolab_vocal)을 선택
VR-Architecture 모드에서 UVR-De-Echo-Aggressive를 선택하고 프로세스 스타트 클릭
이름대로 에코 없애주는 모델이라 에코가 심하지 않다면 생략 가능
작업이 완료되면 (No Echo)파일과 그냥 (Echo)파일 두 개가 생성됨
들어보면 (No Echo)가 에코 사라진 진짜 보이스 파일임. (Echo)는 삭제
2. 파일 선택에서 방금 보정한 노래제목_gaudiolab_vocal_(No Echo) 파일 선택
MDX-Net 모드에서 Reverb HQ 선택 후 프로세스 스타트
어떤 모델인지 잘 모르겠는데 좀 깨끗해지는 기분이 듦(?)
작업 끝나면 (No Reverb)파일이 보이스 파일임
여기까지 해서 그래도 잡음을 더 제거하고 싶을 때
3. 파일 선택에서 노래제목_gaudiolab_vocal_(No Echo)_(No Reverb) 파일 선택
UVR-MDX-Net Karaoke 2 프로세스 스타트
(Vocals)파일과 (Instruments)파일 나옴. Inst파일 버려
이렇게 작업하면 자꾸 파일명이 불어나서 최종적으로
이런 제목이 됨ㅋㅋ
참고로 1~3번 순서대로 안해도 상관 없음
SETP 2. 학습 데이터 정리 (Audacity 사용)
이렇게 해서 끝나면 그나마 다행이지만 끝이 아님
아무리 보정했어도 잡음은 끼어있는 상태.
학습 데이터는 깔끔할수록 좋기 때문에 더 좋은 퀄리티로 만들기 위해서는 어쩔 수 없음.
오디오 편집툴인 Audacity 프로그램으로 무음 부분들을 삭제하고
잡음이 섞여 기계음처럼 들리는 부분들은 컷하는 작업을 한다.
Audacity에 보정한 보컬 파일을 불러오면 이런 화면 뜸
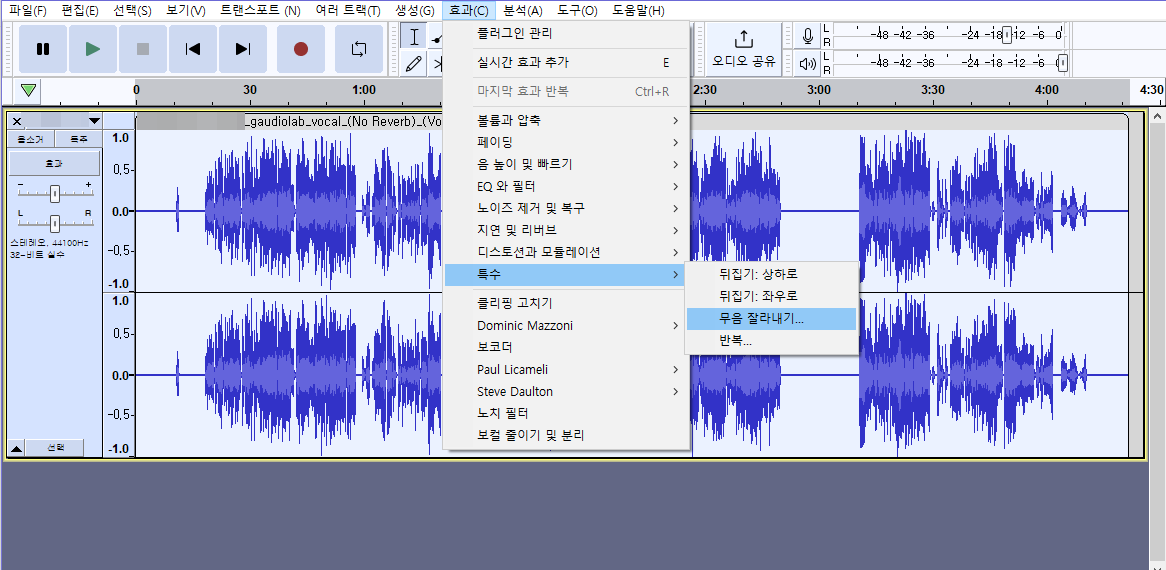
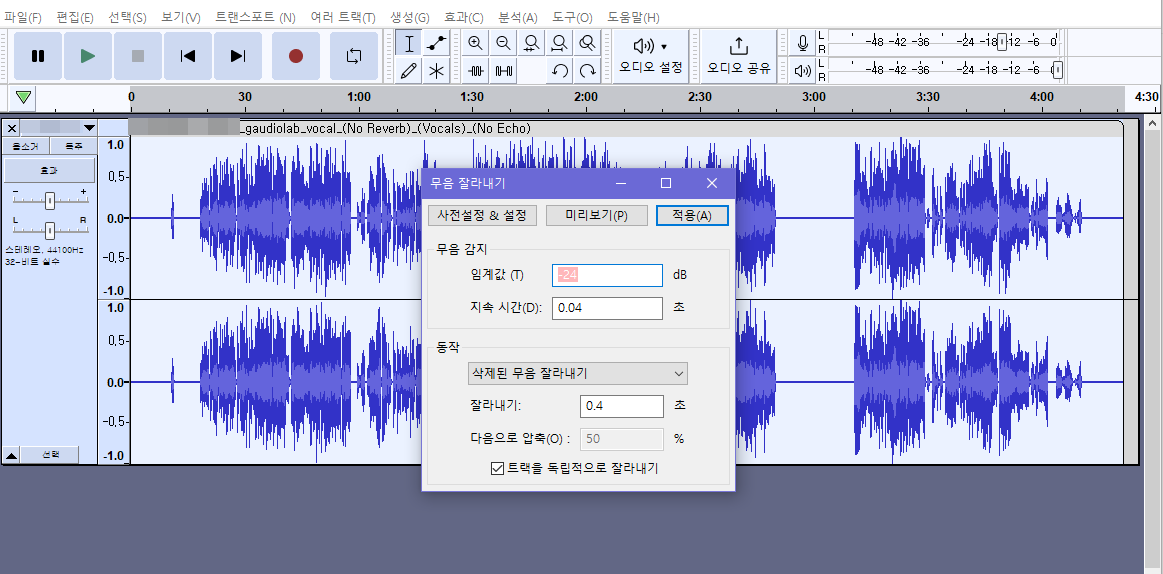
오디오 트랙을 클릭하여 선택>상단 메뉴 효과>특수>무음 잘라내기>적용
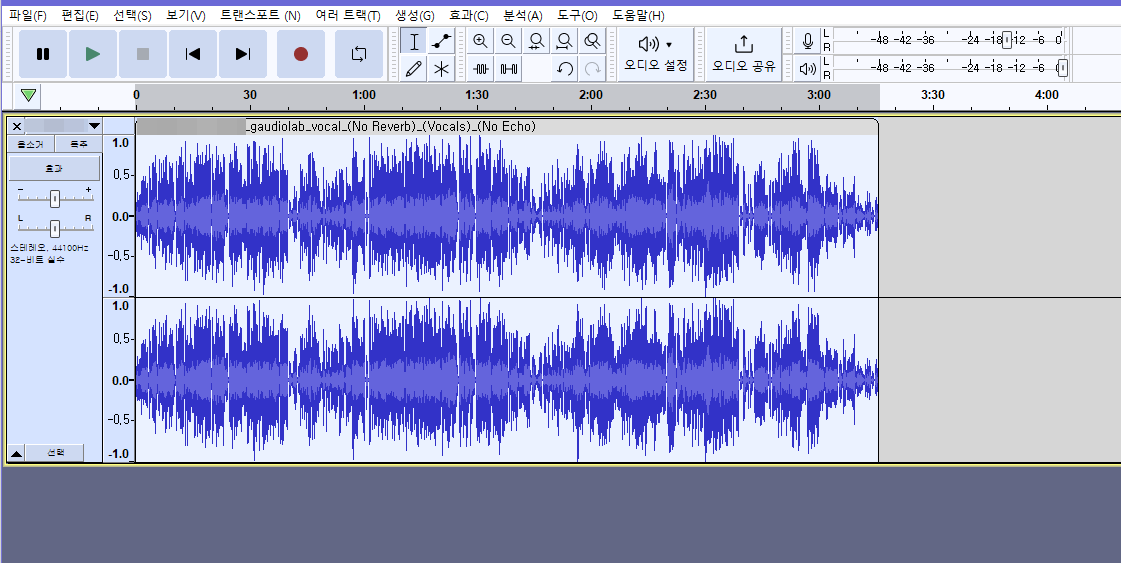
그러면 중간중간 무음이 예쁘게 사라짐
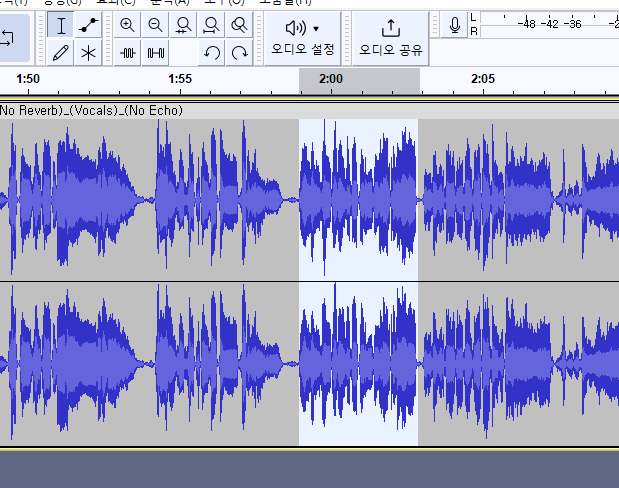
잡음이 심해서 못쓰는 부분은 선택해서 DELETE키 누르면 지워진다.
이렇게 최대한 깔끔한 음성 부분만 남겨서 학습데이터를 꽉꽉 채우는 것이다.
이제 꼴랑 한 곡 작업함.
이 과정을 반복하여 15분 이상의 학습 데이터를 모은다...^^
나도 이 과정이 제일 오래걸렸다.
나는 17분 가량의 데이터를 만들었고, 대부분 노래하는 보이스였으나 평범한 나레이션도 3분 정도 집어넣었음
노래하는 보이스를 추천함
소리소리AI - 쉽고 간편한 AI커버 플랫폼
누구든 쉽고 간편하게 AI커버를 제작할 수 있는 플랫폼
sorisori.ai
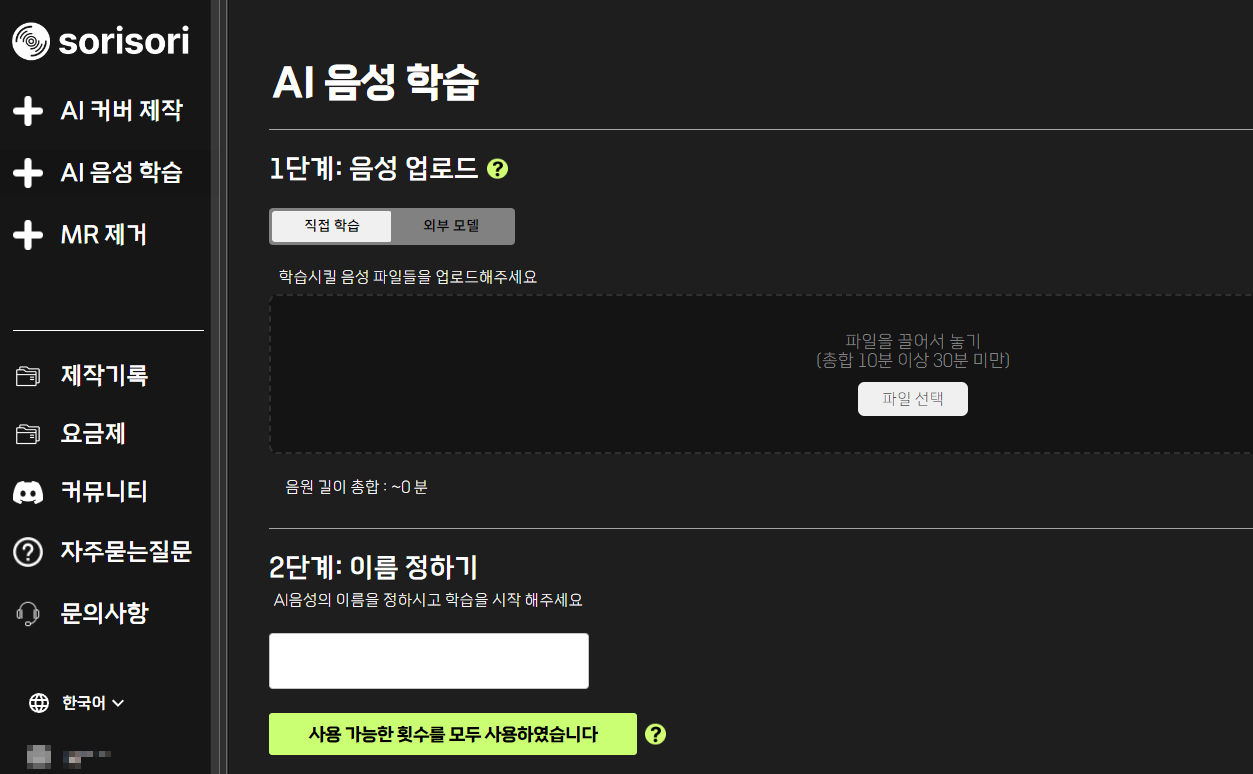
이제 소리소리AI에 접속해서 음성 학습을 시킨다.
기본 플랜은 학습 횟수가 1회라서 이미 학습시킨 나는 사용 가능 횟수가 없다고 나온다.
최대 30분 길이의 학습 데이터를 업로드할 수 있으며, 방금 만들어둔 파일을 전부 업로드하면 됨
학습 시간은 2~4시간 걸린다는데 나는 1시간도 안걸렸음.
SETE 3. 커버곡 보정
커버곡은 ai보컬과 비슷한 음역대로 만들어야 가장 퀄리티 좋게 나왔음.
남녀 전환 같은 건 내가 방법을 모르는 건지 도저히 들어줄 수 없었다.
키조절을 하면 반주까지 키조절해야 해서 이상한 곡이 되어버림
그래서 나는 최대한 음역대 비슷한 곡만 만들고 있다.
학습 데이터를 만들었으니 이제 커버곡만 양산할 수 있겠지?? 하는 달콤한 꿈은 깨자
안타깝게도 위의 보컬 보정 작업을 여전히 반복해야 한다.
이번에는 학습 대상의 보컬이 아닌, 커버곡의 보컬을 보정하는 것이다.
일단 소리소리ai 커버 제작탭에 들어가보면
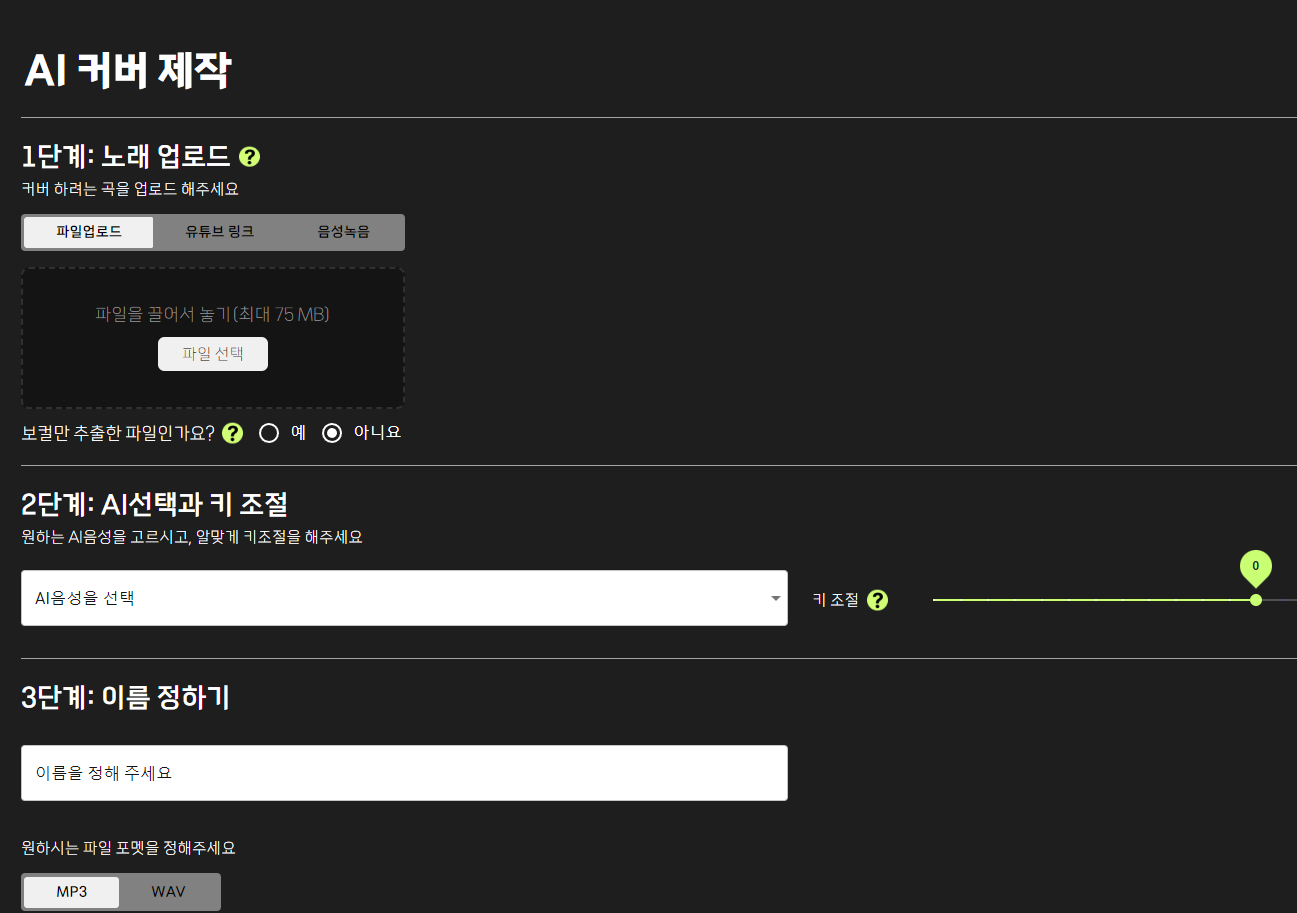
요렇게 뜨는데
커버곡의 유튜브 링크를 넣어서 쉽게 만들 수도 있음
하지만 내가 실험해본 결과 유튜브 링크든 mp3파일이든 원곡을 통으로 업로드해서 만들면 삑사리 나는 부분이 꽤 생겼다.
아마 소리소리ai 자체에서 커버곡의 MR과 보컬을 분리한 뒤 보컬에 학습 음성을 입히는 방식 같은데
손수 공들여 보정한 거랑 차이가 날 수밖에 없는 듯
그러므로 커버곡도 학습데이터 만들 때와 같은 과정을 거쳐준다..
가우디오 스튜디오 보컬 분리 > UVR로 3단 보정을 거쳐 깔끔한 보컬 파일을 만들고
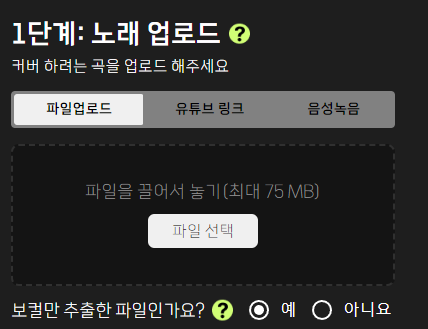
파일을 업로드한 뒤 보컬만 추출한 파일 YES 체크
음성모델 선택하여 커버 제작을 진행함
제작은 대략 1~3분 정도 걸리는 것 같음
완성된 보컬 파일을 다운받아서 Audacity에서 열어줌
반주MR과 ai커버 보컬을 합쳐줄 것임
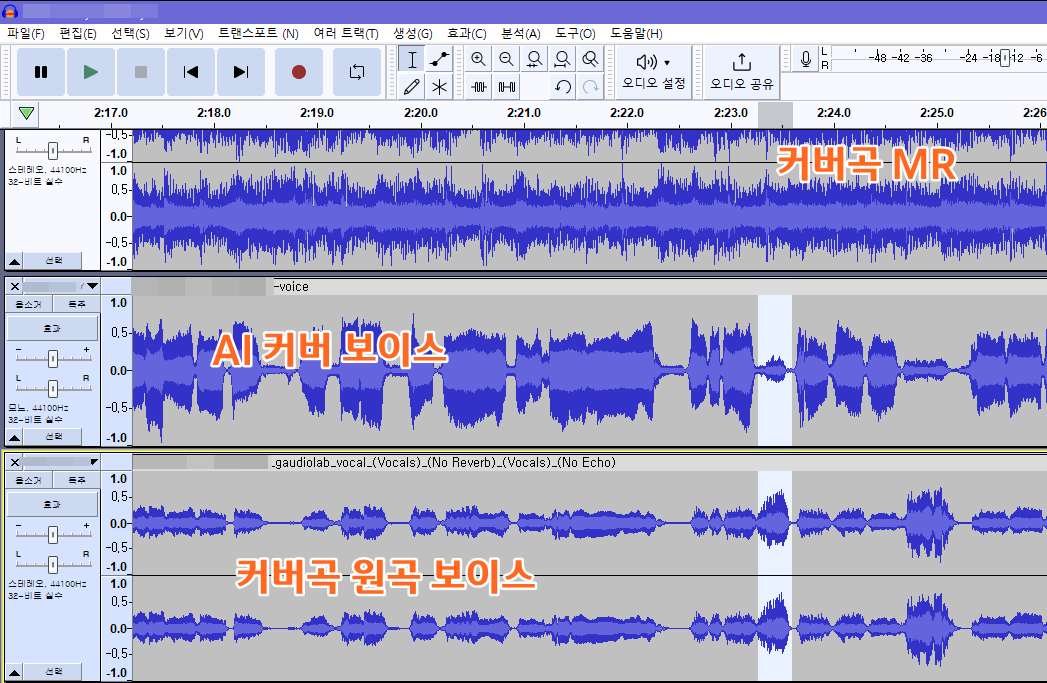
먼저 가우디오로 분리했던 커버곡의 MR을 불러옴
그리고 소리소리ai로 만든 ai커버 보이스도 불러오면 됨
이렇게만 해도 커버곡이 완성되지만
나는 원곡 보이스를 볼륨을 작게 조절해서 깔았음.
왜냐면 보컬 보정을 3번이나 거치면서 굉장히 담백하고 심심한 보컬이 되어버렸기 때문에
MR+AI 보이스만 깔면 뭔가 허전한 느낌이 들었다.
그래서 원곡 보이스를 작게 깔았더니 심심한 느낌도 사라지고 음이탈도 일정부분 보정이 되는 효과가 있었음
참고로 내가 듣는 노래들은 대부분 하드락과 쿵쾅대는 애니송이 대부분이니
한국인들이 좋아하는 어쿠스틱 발라드에는 맞지 않는 방법일지도
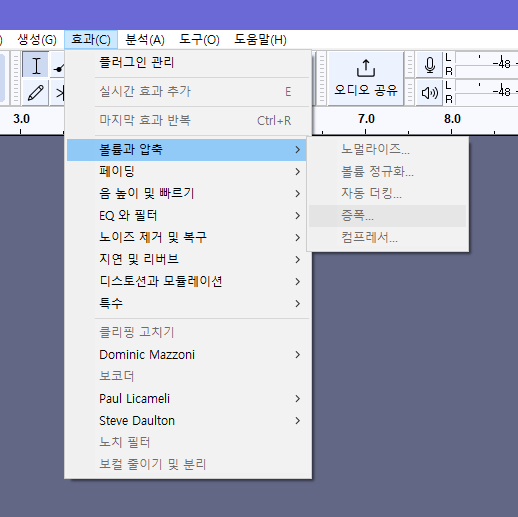
볼륨조절은 증폭 메뉴에서 하면 됨
줄일 땐 -n, 크게 키울 땐 +n 입력
+-1, 2로 조금씩 조절하는게 좋았음
원곡 보이스 볼륨을 너무 크게 하면 여럿이 합창하는 것처럼 들리기 때문에
기본적으로 ai보컬 볼륨을 크게 하고 원곡 보이스는 정말 은은하게 깔아주어야 함
또 많이 활용한 메뉴는 페이드 인/아웃
요건 말 그대로 볼륨 조절을 자연스럽게 할 때 활용했음
그리고 무음처리도 많이 씀
말 그대로 무음으로 만들어버리는 메뉴인데 의도치 않은 잡음을 없애버릴 때,
원곡 보이스가 필요 없는 부분을 삭제시킬 때 위주로 씀
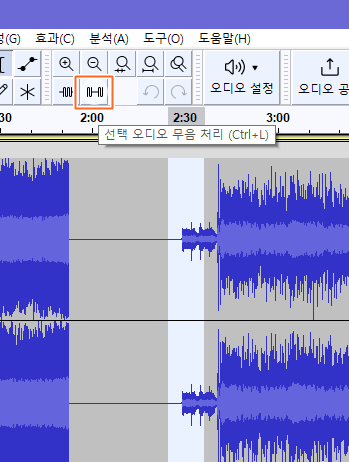
처리할 부분 드래그하고 저 버튼 누르면 무음처리 됨

그리고 ai 보이스가 삑사리 & 깨질 때 처리법
삑사리난 ai 보이스의 볼륨을 아주 작게 줄여버리고
원곡 보이스 볼륨을 높여서 덮어버리는 것임
애초에 음역대 비슷한 노래를 커버하기 때문에 가능한 방법임.
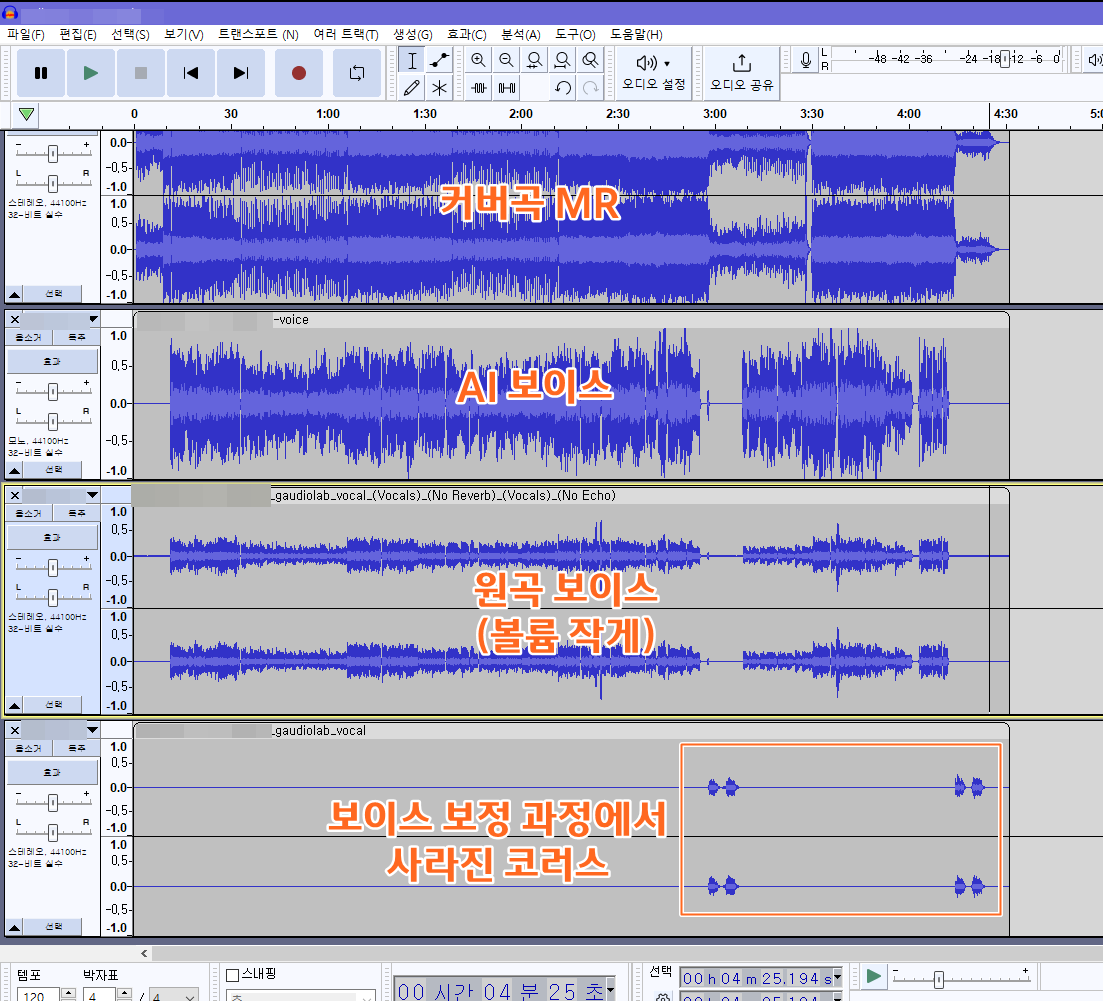
보컬 보정하면서 사라진 코러스들이 있는데
그건 원곡에서 잘라오거나 코러스가 남아있는 보컬 파일을 불러와 끼워넣는다.
이쯤 되니 사운드 재봉사에 빙의해서 오디오 파장을 한땀한땀 따고 있는 나를 발견
다시 말하지만 시간 빌게이츠들만 하시오..ㅠㅠ
내가 만들면서 알아낸 보잘 것 없는 tip
1. 커버곡이든 학습 데이터이든 가능한 코러스가 없는 곡이 좋음
2. 솔로곡으로 만드는게 좋다.. 그룹곡 만들다간 ai 목소리도 덩달아 들쭉날쭉해짐
그룹곡들은 보통 화음 좌르르 깔려있는 건 덤
3. 나는 일본 성우를 ai보이스로 만들었는데, 일본어 데이터로 한국어 노래도 어느정도 커버가 되었다.
가끔 뭉개지는 발음이 있긴 한데 신경쓰일 정도는 아니었음. 팝송은 이제 시도해볼 참임
4. 학습데이터 분량은 최대한 꽉꽉 채우기..
나는 데이터를 17분밖에 채우지 않아서인지 85%정도 비슷한 ai보이스가 만들어졌다.
5. 비슷한 음역대로 만들면 보이스 싱크로율도 많이 올라가지만
창법이 같아서 원곡과 비슷하게 들리기도 한다.
6. 개인에 따라 결과물의 만족도가 높지 않을 수 있고 개쌩노가다 작업이니까 정말 꼭 만들고 싶은 사람이나 츄라이
후기
소리소리ai의 기본플랜 커버곡 제작횟수는 200회인데
아직 내가 30회 정도밖에 사용하지 못했음. 여러가지 실험을 해도 넉넉한 양임
커버곡 하나 만드는 시간이 오래 걸리고
커버하고 싶은 비슷한 음역대의 곡이 많은 것도 아니라 제작횟수는 넘쳐남
하필 내가 원하는 성우님은 음역대가 매우 낮은 남자 성우분인데
싀바 내가 듣는 남자 노래들 음역대가 왜이리 높음?? 이게 남자노랜 여자노랜지 노래방 가도 부르지도 못해 나 여잔데
대표적으로 샤이니.
Satellite 이런 노래 진심 여자도 부르기 어렵지 않음?
다행히 샤이니는 내가 멤버들의 보이스를 너무 좋아해서 애초에 커버곡 만들 생각도 하지 않았지만(화음도 오짐)
다른 남자 보컬들도 생각보다 너무 음역대가 높다.
그래서 커버곡을 만들 수 있는 곡이 너무 한정적ㅜㅜ
제작횟수 남았으니 키 조절하거나 어떻게든 계속 츄라이는 해볼 예정임..